
人大团队破局!拆解LLM黑盒密码,AI幻觉无法根除,刘勇揭开真相

说句实在话,现在咱们刷手机、办工作,几乎离不开ChatGPT、Llama这些大模型。
写文案靠它、解数学题找它、甚至连科研设计分子都能麻烦它,但你有没有静下心想过:这些AI到底是怎么“琢磨事儿”的?
咱们得承认,大模型的工程能力是真够顶的,功能越来越强,渗透到生活工作的方方面面。可它的内在逻辑,却像个上了锁的黑盒,没人能说清道透。
直到中国人民大学刘勇团队的最新综述论文出炉,才算给咱们撬开黑盒搭好了脚手架,把里面的门道梳理得明明白白。


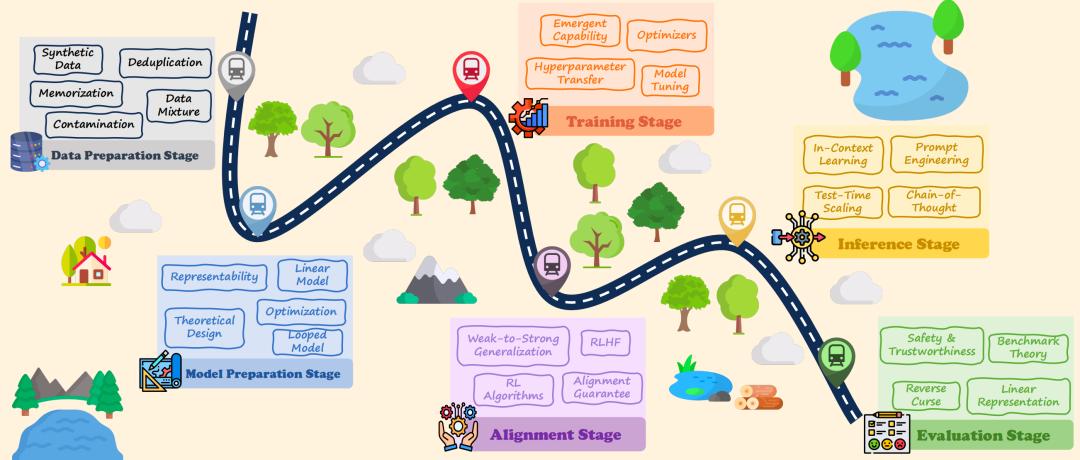
理论破局:六阶段解锁LLM密码
我跟你讲,刘勇团队这篇《Beyond the Black Box》可不是简单堆砌文献、凑字数的“水文”,而是实打实给LLM研究画了张导航图。他们把大模型从诞生到落地的全流程,整合出六大生命周期阶段,相当于把复杂的技术逻辑拆成了六步,从根上帮咱们摸清AI的运作规律。
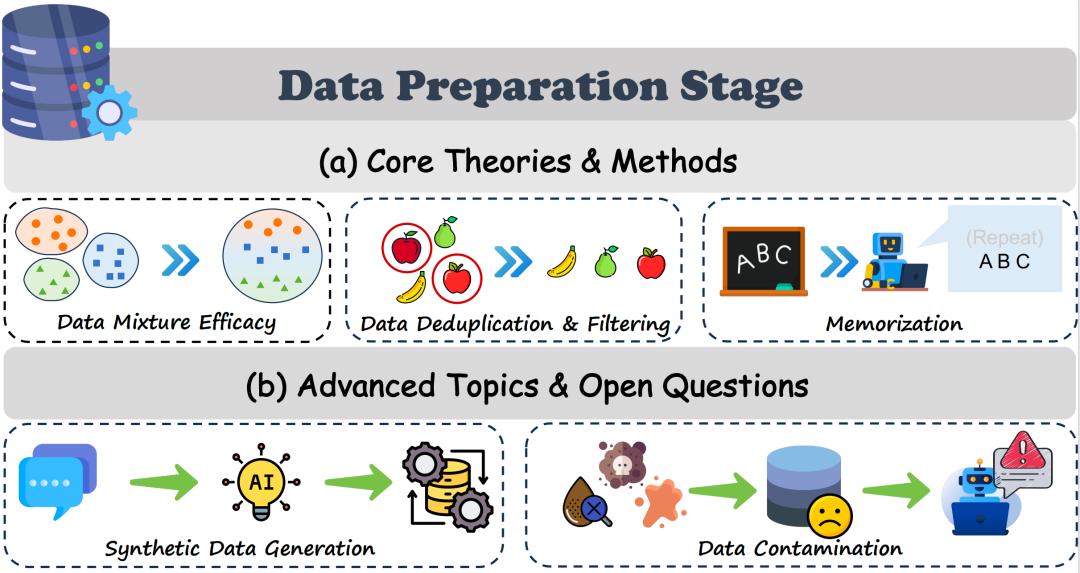
数据准备就是这一切的基石,咱们别觉得模型只是“读得多、见得广”就够了,这里面的学问可深了。

刘勇团队提出的“数据混合定律”就戳破了一个误区:模型的泛化能力,根本不看原始参数堆得多高,核心在于数据的压缩编码长度。就像咱们整理笔记,不是抄得越满越好,而是精简提炼后的内容才管用。
而且数据去重这一步也不能省,不只是为了节省存储资源、减少计算成本,更关键是能降低隐私泄露的风险。研究还发现,那些筛选后的高质量网页数据,效果甚至比人工精挑细选的语料还要顶,这也打破了“人工整理必优于机器筛选”的固有认知。
你发现没,刚新鲜出炉的另一项研究更让人眼前一亮。1月15日,帝国理工和华为诺亚团队联合发文,曝光了一个有意思的发现:大模型的中层会自发形成“协同核心”,运作模式跟人脑处理复杂信息特别像。底层和顶层只负责处理一些冗余杂活,真正管抽象推理、核心决策的,全靠中层这个“关键枢纽”。这一发现,刚好印证了刘勇团队对模型架构表示极限的探讨,让理论有了实打实的实证支撑。
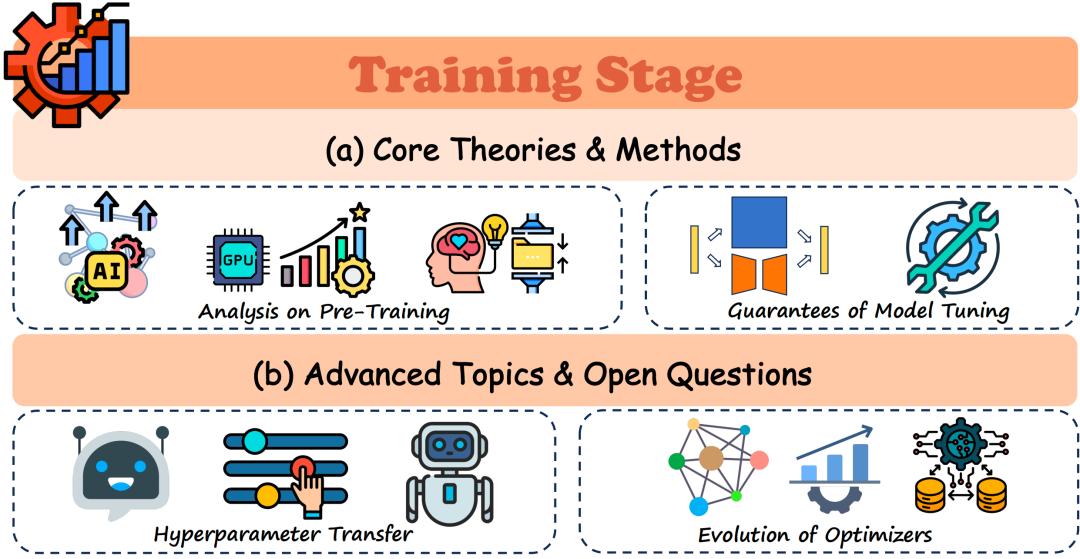
训练阶段更是藏着大模型“变聪明”的核心密码。刘勇团队提出了“压缩即智能”的观点,说白了就是大模型预训练的本质,就是给海量数据做无损压缩,压缩效率越高,后续处理任务的表现就越出色,两者是直接挂钩的。
华为团队的实验也进一步佐证了这一点,他们发现那个“协同核心”不是天生就有的,而是在训练过程中慢慢磨合形成的。要是人为去掉中层的核心节点,模型性能会直接断崖式下跌,就像人没了大脑中枢,瞬间失去行动能力。这也说明,模型训练不只是堆数据、堆参数,精准找到核心训练靶点才更重要。
其实这也符合行业里的新趋势,之前大家都信奉“大力出奇迹”,觉得参数越多模型越强,也就是所谓的“缩放定律”。但随着研究深入,大家发现单纯扩规模的边际效益越来越低,反而像刘勇团队这样,摸清训练机理、找对核心路径,才能让模型真正“变聪明”,而不是空有庞大的参数体量。

落地验证:从机理到实用突破
从另一个角度看,再好的理论也不能飘在天上,能落地、能实用才算真本事。刘勇团队的理论框架,已经有不少研究跟着落地验证了,腾讯云团队1月8日发布的SynLlama就是个典型例子。这个模型专门用大语言模型生成可合成的分子路径,刚好呼应了刘勇团队关注的“合成数据自主进化”问题,把理论变成了实实在在的工具。
咱们通俗点说,SynLlama就是在Llama3模型的基础上做了微调优化,能精准规划出五步以内的分子合成路径,还能生成结构类似的替代分子。
这可解决了AI分子设计领域的一大痛点——以前很多AI设计的分子,只存在于理论中,没法实际合成,纯属“纸上谈兵”。而SynLlama直接打通了理论设计到实际合成的链路,让AI真正能帮上科研的忙。
这背后,靠的正是刘勇团队反复强调的“预训练+微调”机制。其中LoRA这类参数高效微调技术,更是起到了关键作用。它不用对整个模型的参数大动干戈,只在低秩子空间里做优化调整,既能保证模型性能不打折扣,又能节省大量的计算资源和时间,相当于给模型做“精准微创手术”,而非“全身大换血”。
当然,模型越强,安全问题就越关键,这也是刘勇团队在对齐阶段重点探讨的内容。他们明确指出,现在咱们用的那些对齐方法,大多只是“浅层防御”,就像给模型装了个简易防盗门,没法从根本上杜绝风险。
而且研究还发现,用强化学习(RL)做微调,比单纯模仿人类行为的效果好得多,泛化能力更强。这一点在SynLlama的实验中也得到了验证,研究人员只针对中层“协同核心”做强化学习优化,就让模型的分子设计精度显著提升,再次证明了摸清机理、精准发力的重要性。
评估环节也有不少颠覆认知的新发现。刘勇团队通过研究证实,幻觉现象是可计算大语言模型的必然结果,就像人难免会记错事情一样,AI也没法完全摆脱幻觉。这就提醒咱们,平时用大模型的时候,不能完全迷信它的输出,更不能光靠模型自己自评,必须建立更严谨的人工校验和形式化保证体系,才能避免被错误信息误导。
现在行业里也有不少提升评估准确性的尝试,比如用“LLM-as-a-Judge”让模型互相评判,但刘勇团队也提醒,这种方式存在系统性偏见,不能作为唯一的评估标准。真正靠谱的评估,还是要理论结合实证,多维度交叉验证,才能全面掌握模型的真实能力。
结语
大语言模型的发展,早就过了靠“堆参数、堆数据”试错的野蛮生长阶段,正朝着科学严谨的方向迈进。刘勇团队的六大阶段框架,就像一盏明灯,给行业指明了研究方向;而“协同核心”“SynLlama”这些研究成果,就是铺在这条路上的基石。黑盒不会一下子被完全撬开,但理论和实证的双向奔赴,正在让咱们从“知道AI好用”,慢慢变成“知道AI为什么好用”。未来的AI竞争,拼的不是谁的模型更大,而是谁更懂机理、更能精准发力,这才是AI可持续发展的核心逻辑。






